
Even if you are not aware, you are using feedback loops to build software every day. Your team’s performance is actually highly correlated with how you utilize these feedback loops. During a recent development project, I once more saw firsthand how crucial feedback loops are in software development. In this blog post, I would also like to remind you of how important they are.
Every project has its own difficulties, and every team can make mistakes. This is normal in software development. What differentiates high-performing teams from the others generally boils down to what they do with the feedback they get. The feedback could be a failing test case from the pipeline, a monitoring alarm going off on production, or a sneaky bug that managed to pass all existing quality gates and made its way to production.
Sneaky bugs require a post-mortem, an analysis to understand how all quality gates were bypassed. The questions that need to be asked here are “What is the possibility of this ever happening again?” and, if it is probable, “What can we do to prevent it ever happening again?
Cost of fixing defects
Before anything else, I would like to show you this research from IBM, Integrating Software Assurance into the Software Development Life Cycle (SDLC). As you can see from the graphic below, noticing a design flaw in the earlier stages of development can be 100x cheaper than noticing it on production. If you notice it during implementation, it is 13x cheaper.
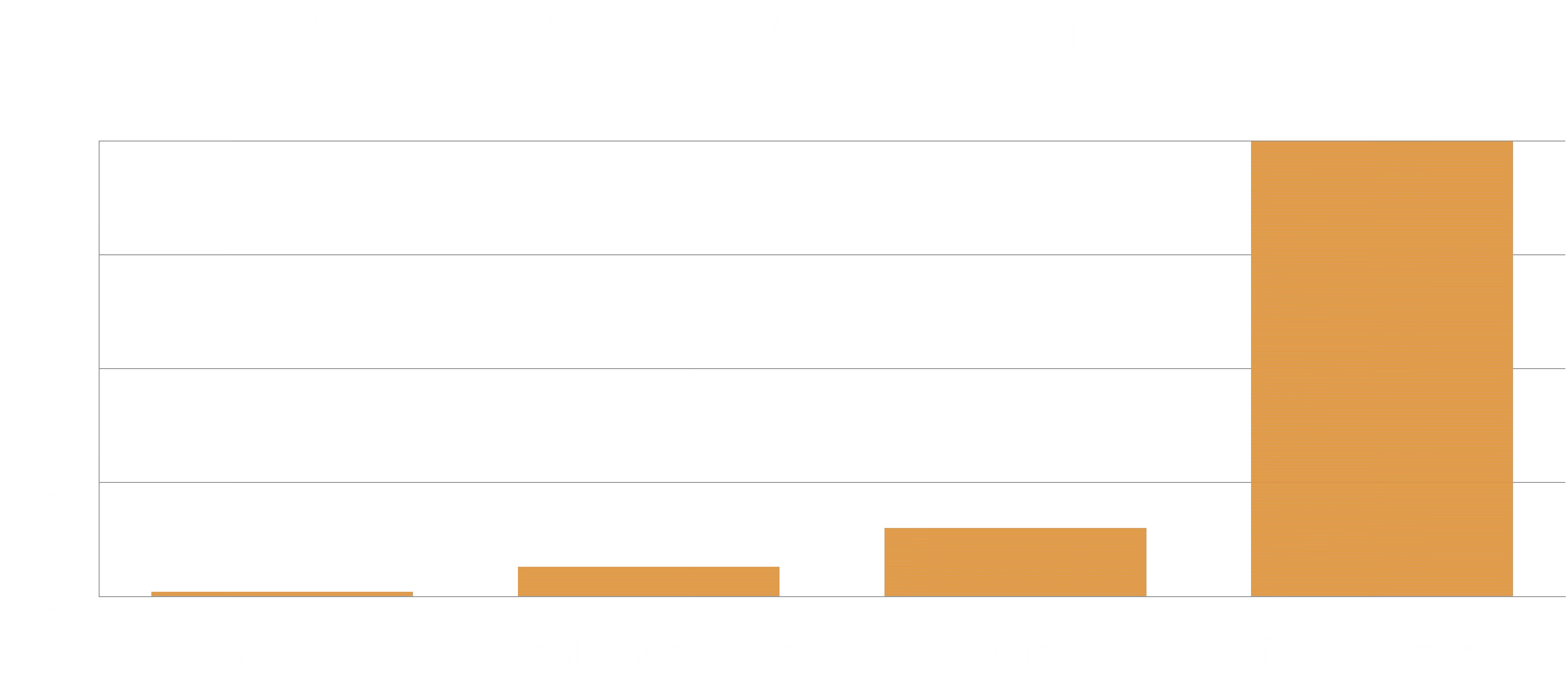
I want you to analyze this graph as if you are investing money, time, and resources; “Think like an investor” here.
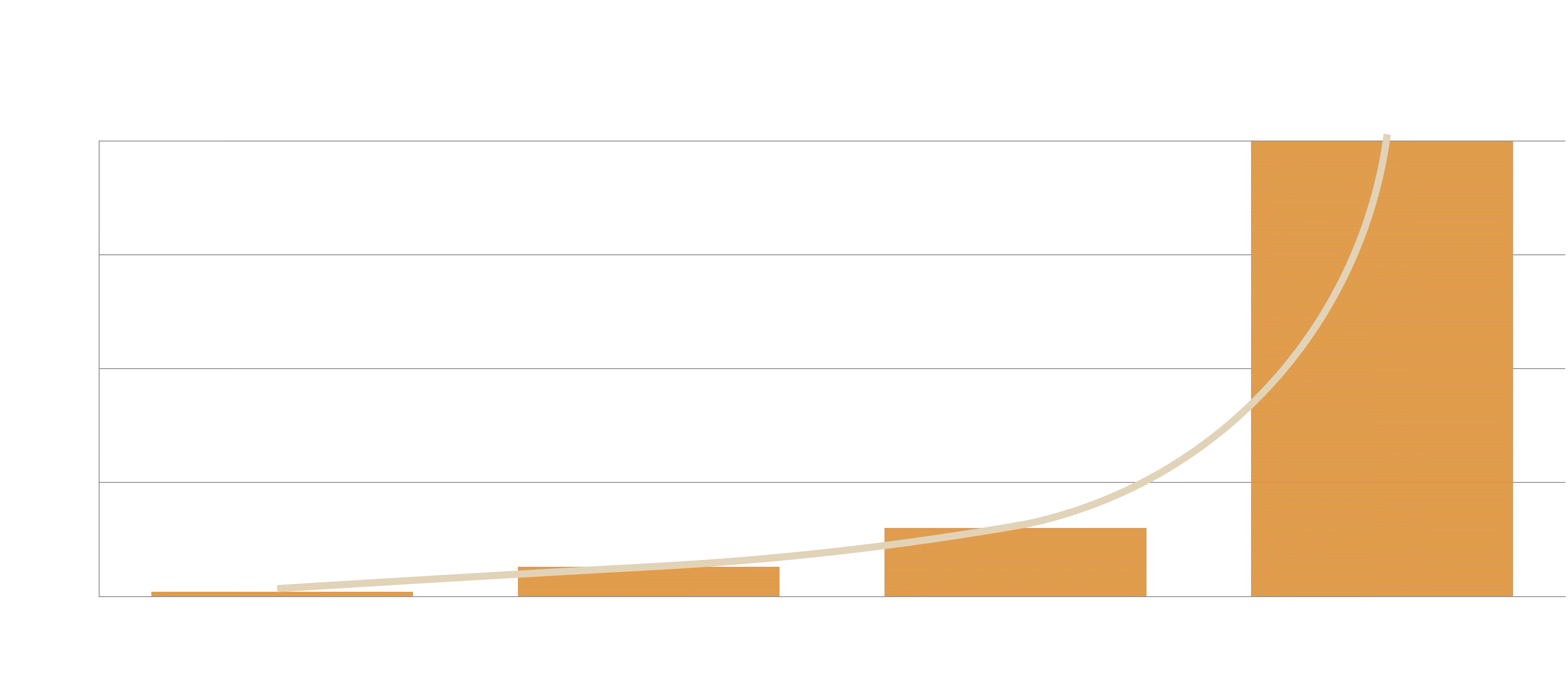
If you can create a feedback loop that will find a bug, detect a design flaw or similar in the earlier stages of development, you can actually get an exponential payoff.
Real world examples from a recent project
With a group of highly skilled and experienced engineers, we worked on a high-pressure, hard-deadline project that would allow significant cost savings for our company. Since we had a hard deadline, time became a constant for us in the Iron Triangle, which also made time scarce for us. We had to make sure that every effort and every moment we spent mattered for the end result. We constantly balanced scope and quality to meet the deadline.
What I noticed during this period was the effectiveness of developer tools. Small investments we made in developer tools, created feedback loops which paid off so quickly that the time poured into these small developer tools became insignificant even under the high-pressure deadline.
Our configuration-heavy project had a few manual steps (copy/paste) to configure environments. Required time to completely automate this process was ~10000x more expensive than keeping it manual. However, an hour invested in comparing the configurations per environment in the CI/CD pipeline saved hours of work compared to the moment we realized that we actually deployed wrong configuration to production.
Another important advantage of working with experienced engineers was that most common feedback loops immediately found their place in our SDLC (Software Development Lifecycle). There have been many cases of active discussions to add more quality gates that will give us feedback earlier to notice problems before they occur on production. What are these common feedback loops? Where should you start? Are there specific tools that can help you create these feedback loops? Can you or should you take additional actions if you are working on the cloud, using Generative-AI? Let’s discuss these questions in the following sections.
Where should you start?
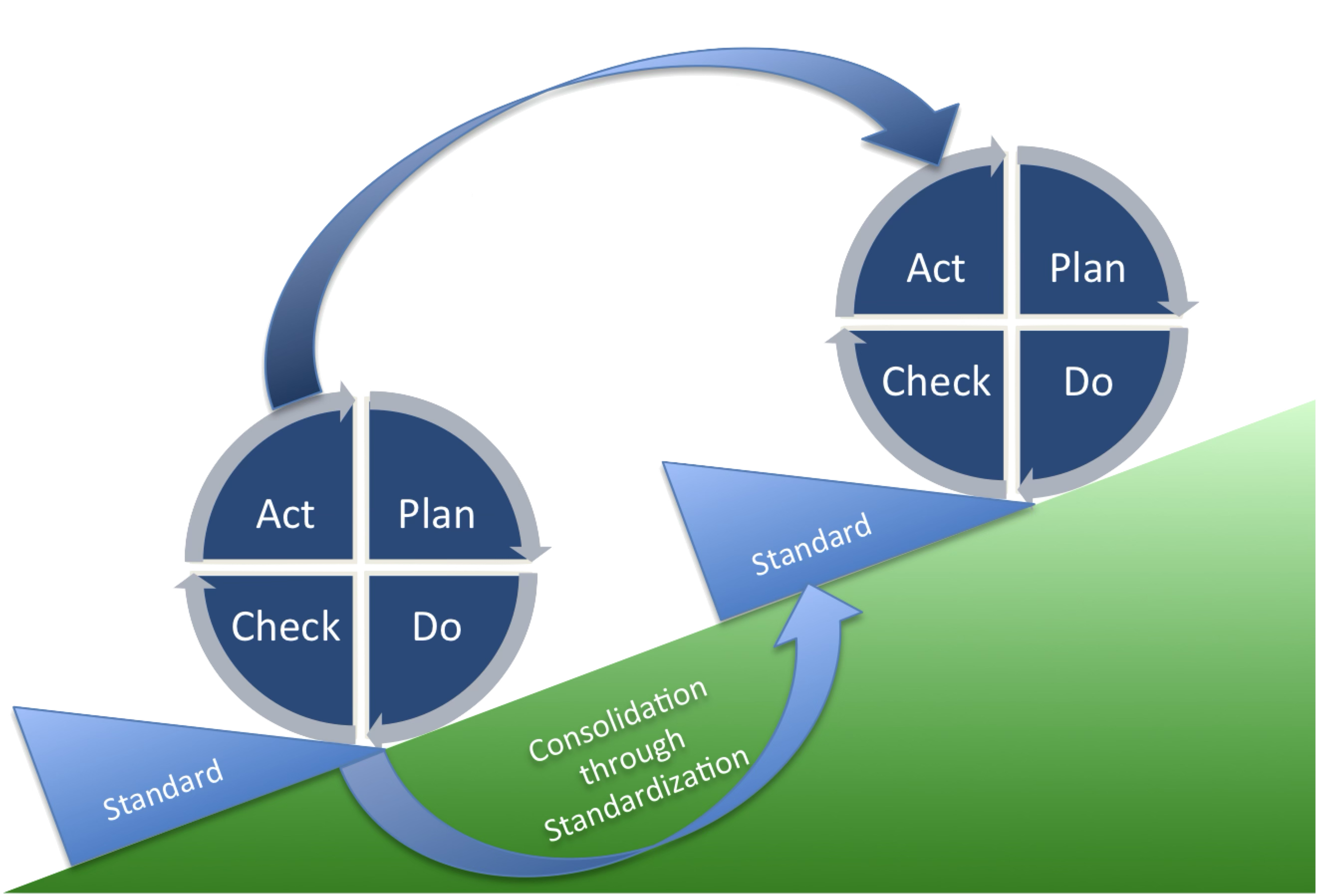
DevOps Infinity Cycle must be the starting point when working on feedback loops in your SDLC (Software Development Lifecycle). In the era of AI and cloud development, we have more tools to build on this construct. In the following sections let’s discuss some possibilities.
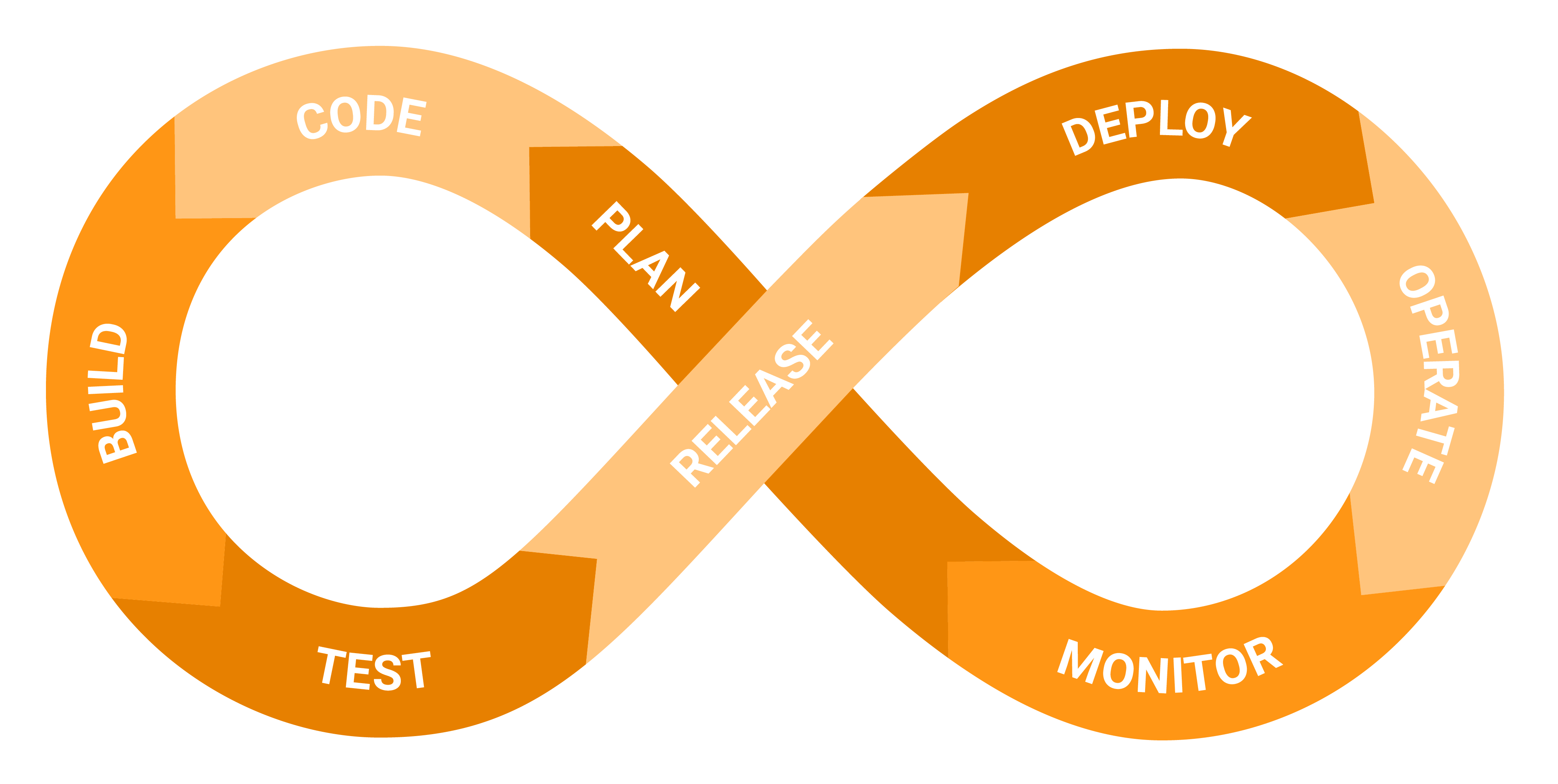
Let’s go over the DevOps Infinity Cycle stages together and discuss one by one what could be good options.
DevOps Infinity Cycle
Plan
Everything starts with a good plan. If you check the Cost of fixing defects section, any bug, design flaw that we can notice in the Plan phase can be 100x cheaper to fix.
At this phase, it is imperative that you understand the domain and question Why/What/How clearly about the project. There are many possible approaches here. One I like to use is 5W1H approach. 5W1H is a problem-solving approach that helps in obtaining fundamental information about a given problem or situation. This type of checklist is designed to guide the gathering of information and understanding of any current state using six key words: What/Who/Where/When/Why/How.
You should ask questions like:
- What is the problem statement?
- Why are you building this particular project or feature? Is it a good investment?
- Who will be the main audience?
- How should you solve this problem? What kind of solution would strike the balance between cost and value generation?
When the answers to above questions are clear, next step is to also have a Testing Strategy. Determine how you will validate your assumptions and solution.
If you are planning to build your solution on the cloud, you should check your assumptions against the best practices and frameworks provided by the cloud provider. For example, if you are building on AWS, you should check your assumptions against AWS Well Architected Framework. Do your assumptions still hold or should you go back to the drawing board?
Generative-AI
Use Generative AI for documentation, note taking in meetings, summaries of your decisions, gap analysis or to create ADRs.
Create your own context.
Did you know that according to DORA Report 2023, quality of internal documentation has an almost 13-fold impact on organizational performance? Guess who is good at writing documentation? Yes, Generative-AI can do that for you once you give the correct template to it.
Code, Build and Test phases will form a feedback loop by themselves and these phases will be the ones that you will be looping over and over again at the beginning of a project. This loop here should execute like a powerful engine.
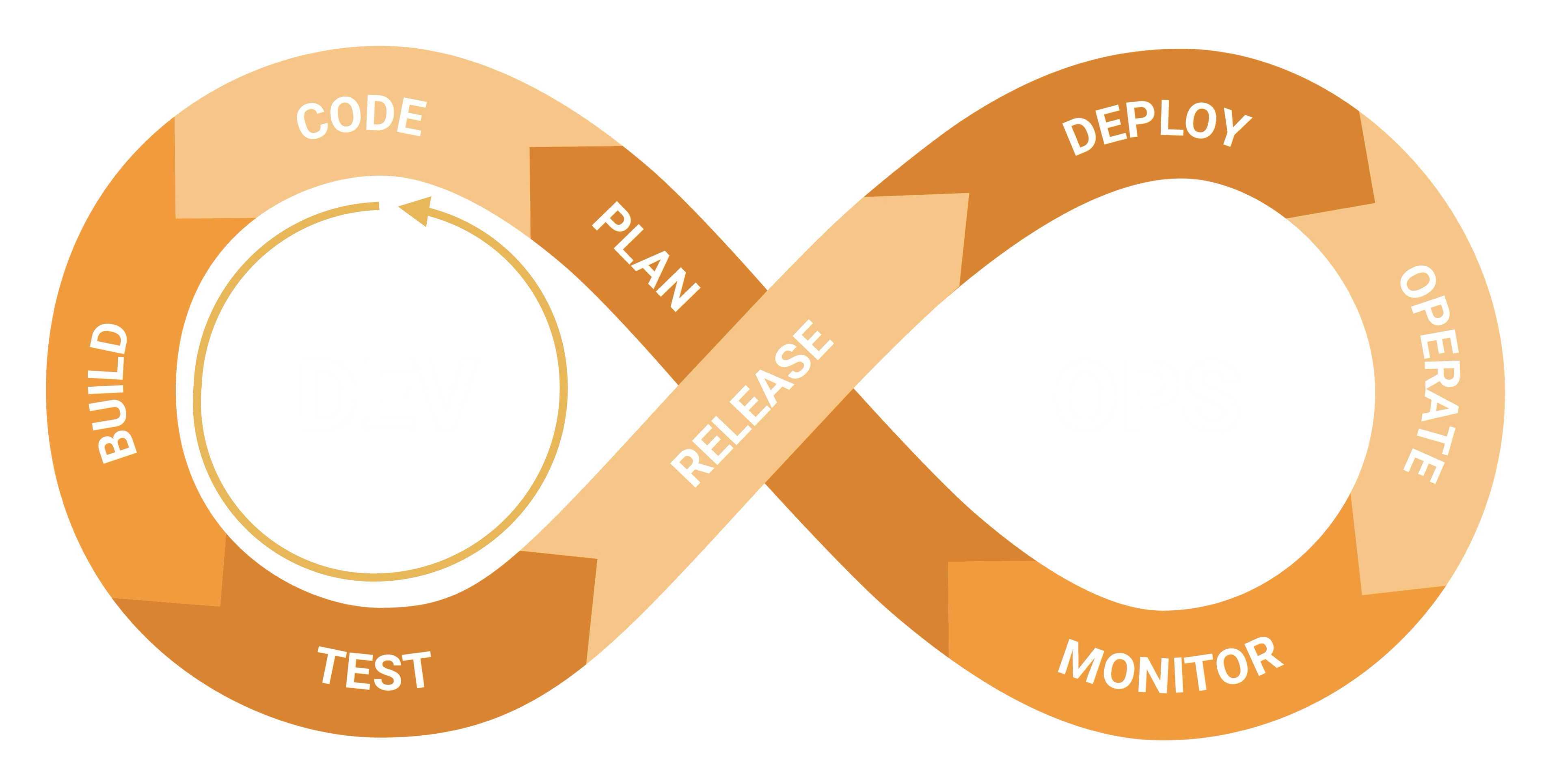
Try to make investments here to make this loop as seamless as possible! This is the place where your investments can really matter.
Code
Coding phase must be intertwined with automated testing. Automated testing creates fantastic feedback loops for us. We should use it to its full extend. Testable code has also high correlation with maintainable code. We should start with automated testing together with development.
There are also other tools here that can create valuable feedback loops for us. Let’s name a few.
Use a static code analysis tool (SAST - Static Application Security Testing) during development. Simple stuff that you can miss in code reviews can be caught by these tools. Some of them also helps you track your code coverage with tests. Use this as a feedback loop to improve your tests. Have thresholds.
You can already integrate observability (o11y) when you start development and trust me, it will make a huge difference in your development especially with code bases that have complex computations and interactions. We will touch on this again in Test phase.
Enforce mandatory Code Reviews, use AI where you can. Code Reviews can create bottlenecks in DevOps Team, but they are great for both as a quality gate and also collaboration moment within the team. AI code reviewers can help you with Code Reviews and create a faster feedback loop.
Invest in developer tools. As my example in Real world examples from a recent project, one hour of investment in a developer tool can save hundreds of hours. If you can prevent an error before a production deployment, your investment has already paid for itself. Or a production error can be a trigger to create a developer tool to prevent it ever happening again.
Think like an investor.
If you are working on the cloud, you can consider options that will allow you to build more on your local machine instead of deploying to the cloud. This approach will allow you to create a faster feedback loop and will also help you to reduce costs. For example, if you are working on AWS, you can use LocalStack to build your functionality faster.
Generative-AI
Use an AI assistant to help you with coding and Code Reviews. Push it to its limits to find bugs as early as possible.
Build
I hope I don’t need to write in detail to use a CI/CD pipeline to automate tasks for build/test/publish/deployment anymore. Hopefully you are already doing it.
What I can tell instead is to keep an eye on your pipeline runs and optimize them. You should set thresholds for how much time each step is supposed to take and take vigorous action if your thresholds are breached.
Integrate and scan for security at early stages. Heed to what Dependabot says about your package vulnerabilities. Adhere to best practices against supply chain attacks depending on your programming language.
Test
If you have already did your homework in Plan phase, you should already have a Testing Strategy. Create your Testing Plan in detail according to your Testing Strategy. You should layer your tests in such a way that crucial functionality is covered at least in one layer and overlap between testing layers (unit/integration/end-to-end) is as small as possible for efficiency.
Since we already have pipeline, we should also keep an eye on testing duration and optimize when necessary.
Using a DAST (Dynamic Application Security Testing) tool can help you find vulnerabilities in your application immediately during testing and you can prevent them from being deployed to production.
There will be parts in the codebase where you can test locally and there will be parts you can’t unless you make a deployment.
Here, it is crucial to make a good decision on what you can test locally. Because local testing will be faster, cheaper and ~13 times more efficient. It will give you a faster feedback loop on what doesn’t work. Maybe a code structure change just to be able to test locally is not a bad investment?
Guess what? O11y integration helps with testing as well. If you run a local Jaeger container and point your codebase to it, you can collect OpenTelemetry Events directly from your tests. This approach actually makes a huge difference in pinpointing bugs and understanding the behavior of your codebase with low cognitive overload. Switching to another OpenTelemetry Backend is just a configuration change when deployed to the cloud.
Generative-AI
You probably already know but Generative-AI is pretty good at writing tests once you establish standards. You can leverage this capability and increase your test coverage significantly.
Testing is one of the most powerful feedback loops that we have. We should use it to its full extend.
Release
During this phase, the most important thing you should do is to generate release notes and use semantic versioning so that you can refer back to the changes in the future.
The quality of the phases after this one will rely on versioning created in this phase.
Deploy
In deployment phase, it is imperative to deploy using a CI/CD pipeline. This automated process will allow you to:
- Keep an eye on how long does it take to deploy a new version.
- Collect other metrics on your deployments (i.e. DORA Metrics).
- Run your DAST (Dynamic Application Security Testing) tool to find vulnerabilities in your application before deployment to production.
DORA Metrics are core to any DevOps team. Additionally, I personally like to track the duration of the deployments and use it as a feedback loop to optimize the deployment process.
Operate
Before we get to the Operate phase, we should have a proper incident management process to support our users.
We should also gather data about the usage of our application. This data can be used to feed back to the earlier stages of DevOps Infinity Cycle.
We should also add alerts to business metrics.
Generative-AI
Generative-AI can be used to pinpoint root causes of problems faster during incident management. Leverage this capability to create a feedback loop for your incident management process.
Monitor
For monitoring, health metrics for all your critical resources are crucial.
If you have been integrating o11y (Observability) during development, you should now have a good understanding of your applications behavior during normal and faulty operation. This will help significantly for incident management as well.
Keep running your DAST (Dynamic Application Security Testing) tool to find vulnerabilities in your application and fix them proactively.
Now that we have covered all phases of the DevOps Infinity Cycle, let’s discuss how we can create feedback loops for our team and organization. The feedback loops we create within DevOps Infinity Cycle will help us during software development. Feedback loops we create on top of them in “Team Level” and “Organization Level” will help us to improve the engineering excellence to the next level.
Feedback Loops for your Team
DevOps Teams must also invest in creating a PDCA (Plan-Do-Check-Act) cycle to improve the engineering excellence through continuous improvement.
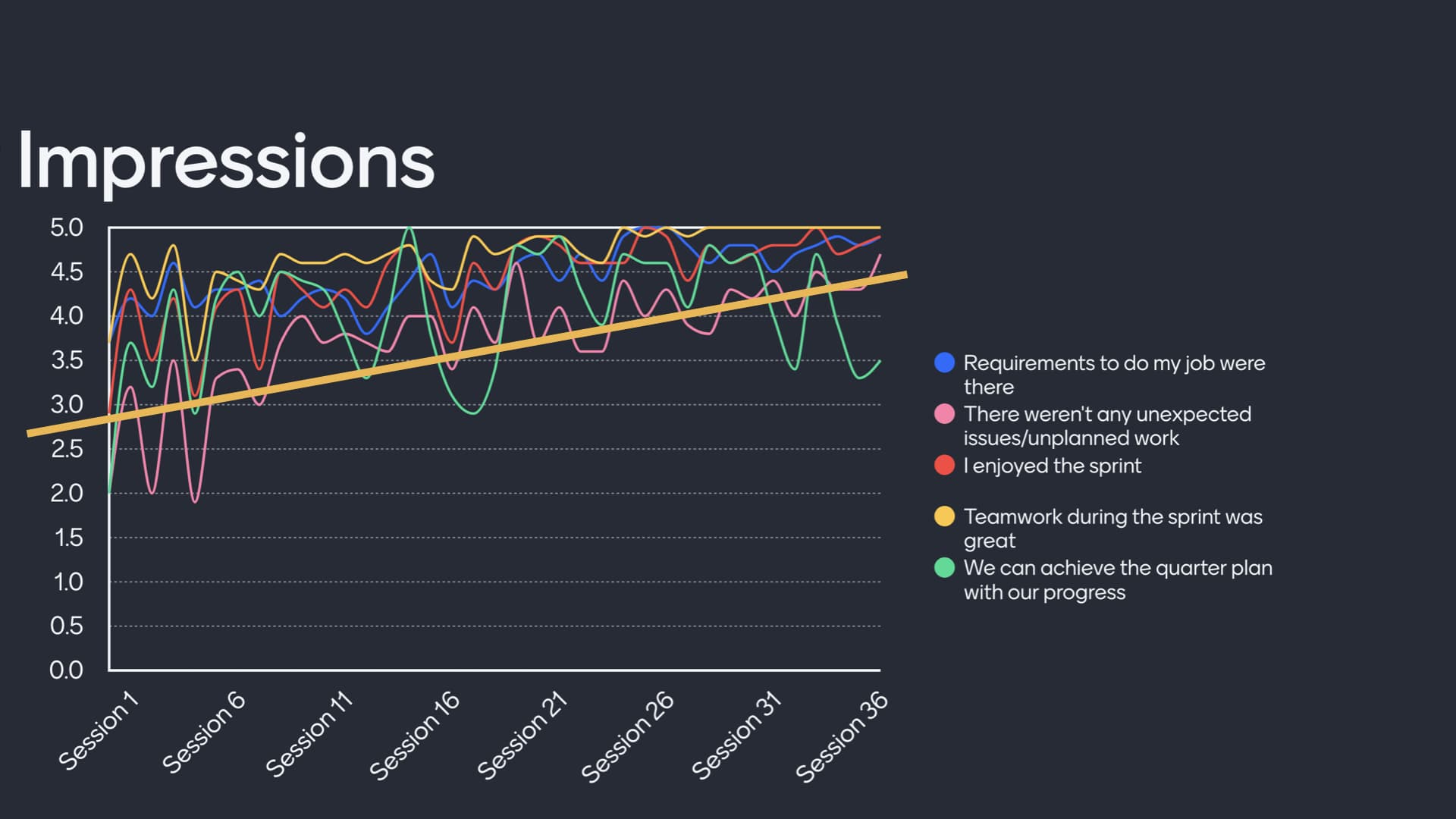
Retrospective meetings are the great to utilize for this activity. I know, you find them boring and you don’t want to talk about how you feel in front of your team members. I believe the way to decrease friction is to talk through numbers.
Use retrospective meetings effectively:
- Have a self assessment on team happiness and overall team performance.
- Go over your DORA metrics to detect fluctuations and assign tasks to do root cause analysis.
- Determine quality gates and make it a standard.
In my teams, I created a 5 statement anonymous survey to get feedback from the team at the end of every sprint. This allows us to assign numbers to the general feeling of the team and opens the door for more detailed feedback and discussions during the retrospective meeting.

What matters is the progress and visualizing the progress. Through Kaizen (small iterative improvements), this approach creates a feedback loop on team level and you can take action if you notice problems. A detected problem can be a trigger for a new quality gate and can become a new standard in the PDCA (Plan-Do-Check-Act) cycle.
Feedback Loops for your Organization
Organizations also need a feedback loop to improve their decision making. In my experience, organizations who are working with engineering teams must also collect DORA Metrics per team.
We have many strategic decisions and from upper management it is extremely difficult to notice the effects of these decisions.
Beauty of DORA Metrics is that they are universal. It doesn’t matter what kind of application you are building. If all teams were to share their performance metrics on organizational level, the organization would also have its own metrics.
We already know that the shared data must not be used to compare teams. The teams are operating in different contexts. It would be comparing apples with oranges which doesn’t make any sense. But if say, all teams were reporting their DORA Metrics and we simply observe the trends of these metrics, it would allow possibility to:
- Visualize the performance of an individual team over a timeline.
- This will allow you to self-reflect on your team’s performance.
- Let the upper management to see the performance and decide better on where to invest in your team.
- Create formulas on organizational level to visualize and reflect on upper management decisions looking at the overall context of all teams.
Conclusion
I started this article showing you the cost of fixing defects in different stages of the development lifecycle. Then I gave you a real world example of how feedback loops can help you save your time and resources. We went over the DevOps Infinity Cycle and discussed how you can create feedback loops for your team and organization. To highlight the most important points:
- Spend just enough time on planning, not too little, not too much. Try to find the sweet spot.
- Focus on feedback loops where you iterate the most (Code/Build/Test). Any defect detected in these phases can be fixed quickly and with low cost.
- “Think like an investor”. If you can create a feedback loop that will find a bug, detect a design flaw or similar in the earlier stages of development, you can actually get an exponential payoff.
- Set thresholds for testing, deployments, and other metrics (DORA Metrics) and go after optimizations vigorously if thresholds are breached.
- Create a PDCA cycle for your team. This will help you to improve the engineering excellence through continuous improvement.
- Help your organization create feedback loops. Allow them to reflect on their decisions and make better investments.
During this journey we added additional actions you can take if you are working on the cloud, and if your team is using Generative-AI.
I hope you enjoyed reading this article. If I managed to remind you the importance of feedback loops and spark a few ideas on how you can create a few for your team and organization, then my target is achieved. Thank you for reading.
Happy coding!